Télécharger le PDF du cours

Nous n’avons accès qu’à trois métacaractères au sein des classes de caractères : les métacaractères ^, - et \. A l’extérieur des classes de caractères, cependant, nous allons pouvoir en utiliser de nombreux autres.
Nous allons présenter ces différents métacaractères dans cette leçon.
Le point
Le métacaractère . (point) va nous permettre de rechercher n’importe quel caractère à l’exception du caractère représentant une nouvelle ligne qui est en PHP le \n.
<!DOCTYPE html>
<html>
<head>
<title>Cours PHP & MySQL</title>
<meta charset="utf-8">
<link rel="stylesheet" href="cours.css">
</head>
<body>
<h1>Titre principal</h1>
<?php
$masque1 = '/./';
$masque2 = '/[.]/';
$chaine = 'Pierre, 29 ans. Et vous ?';
preg_match_all($masque1, $chaine, $tb1);
preg_match_all($masque2, $chaine, $tb2);
echo '<pre>';
print_r($tb1);
echo '<br>';
print_r($tb2);
echo '</pre>';
?>
<p>Un paragraphe</p>
</body>
</html>
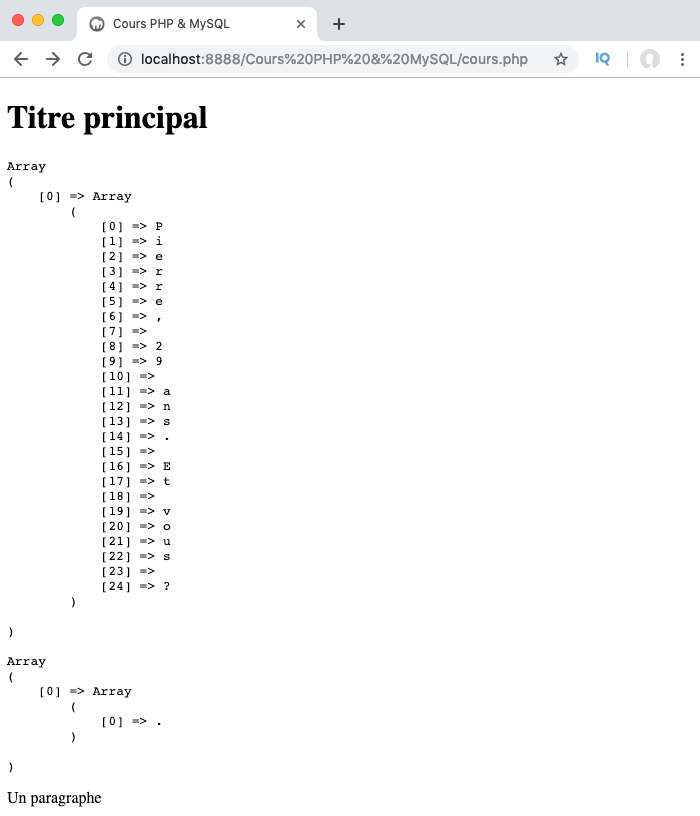
Comme vous pouvez le voir, le point a un sens bien différent selon qu’il soit spécifié dans une classe ou en dehors d’une classe de caractères : en dehors d’une classe de caractères, le point est un métacaractère qui permet de chercher n’importe quel caractère sauf une nouvelle ligne tandis que dans une classe de caractère le point sert simplement à rechercher le caractère point dans notre chaine de caractères.
Encore une fois, il n’existe que trois métacaractères, c’est-à-dire trois caractères qui vont posséder un sens spécial à l’intérieur des classes de caractères. Les métacaractères que nous étudions dans cette leçon ne vont avoir un sens spécial qu’en dehors des classes de caractères.
Les alternatives
Le métacaractère | (barre verticale) sert à séparer des alternatives. Concrètement, ce métacaractère va nous permettre de créer des masques qui vont pouvoir chercher une séquence de caractères ou une autre.
<!DOCTYPE html>
<html>
<head>
<title>Cours PHP & MySQL</title>
<meta charset="utf-8">
<link rel="stylesheet" href="cours.css">
</head>
<body>
<h1>Titre principal</h1>
<?php
$masque1 = '/er|re/';
$chaine = 'Pierre, 29 ans. Et vous ?';
preg_match_all($masque1, $chaine, $tb1);
echo '<pre>';
print_r($tb1);
echo '</pre>';
?>
<p>Un paragraphe</p>
</body>
</html>

Ici, on utilise le métacaractère | pour créer une alternative dans notre masque. Ce masque va nous permettre de chercher soit la séquence de caractères « er » soit la séquence « re » dans la chaine de caractères à analyser.
Les ancres
Les deux métacaractères ^ et $ vont nous permettre « d’ancrer » des masques.
Le métacaractère ^, lorsqu’il est utilisé en dehors d’une classe, va posséder une signification différente de lors de l’utilisation dans une classe. Attention donc à ne pas confondre les deux sens !
Utiliser le métacaractère ^ en dehors d’une classe nous permet de rechercher la présence du caractère suivant le ^ du masque en début de la chaine de caractères à analyser.
Il va falloir le placer en début de du masque ou tout au moins en début d’alternative pour qu’il exprime ce sens.
Au contraire, le métacaractère $ va nous permettre de rechercher la présence du caractère précédant le métacaractère en fin de chaine.
Il va falloir placer le métacaractère $ en fin de du masque ou tout au moins en fin d’alternative pour qu’il exprime ce sens.
Prenons immédiatement quelques exemples concrets :
<!DOCTYPE html>
<html>
<head>
<title>Cours PHP & MySQL</title>
<meta charset="utf-8">
<link rel="stylesheet" href="cours.css">
</head>
<body>
<h1>Titre principal</h1>
<?php
$masque1 = '/^p/'; //Cherche "p" en début de chaine
$masque2 = '/^p|^P/'; //Cherche "p" ou "P" en début de chaine
$masque3 = '/^[A-Z]/'; //Cherche une majuscule en début de chaine
$masque4 = '/\?$/'; //Cherche "?" en fin de chaine
/*Cherche une chaine de deux caractères qui commence par "P" et finit
*par "?"*/
$masque5 = '/^p\?$|^P\?$/';
$chaine = 'Pierre, 29 ans. Et vous ?';
if(preg_match($masque1, $chaine)){
echo '"p" trouvé en début de chaine <br>';
}else{
echo '"p" non trouvé en début de chaine <br>';
}
if(preg_match($masque2, $chaine)){
echo '"p" ou "P" trouvé en début de chaine <br>';
}else{
echo '"p" ou "P" non trouvé en début de chaine <br>';
}
if(preg_match($masque3, $chaine)){
echo 'La chaine commence par une lettre majuscule de A à Z <br>';
}else{
echo 'La chaine ne commence pas par une majuscule de A à Z <br>';
}
if(preg_match($masque4, $chaine)){
echo '"?" trouvé en fin de chaine <br>';
}else{
echo '"?" non trouvé en fin de chaine <br>';
}
if(preg_match($masque5, $chaine)){
echo 'La chaine est "p?" ou "P?"<br>';
}else{
echo 'La chaine n\'est pas "p?" ou "P?"<br>';
}
?>
<p>Un paragraphe</p>
</body>
</html>

Nos masques commencent ici à être relativement complexes et il faut bien faire attention à leur écriture. Avant tout, j’ai dû protéger le caractère ? à chaque utilisation dans mes masques car c’est également un métacaractère que nous allons étudier juste après et car ici je souhaitais véritablement chercher la présence du caractère « ? » et non pas donner un sens différent à mon masque.
Mon premier masque nous permet de chercher la présence d’un « p » minuscule en début de chaine grâce au métacaractère ^ placé en début de masque.
Mon deuxième masque nous permet de chercher la présence d’un « p » minuscule ou d’un « P » majuscule en début de chaine. Ici, vous pouvez remarquer qu’on utiliser deux fois le métacaractère ^. En effet, ce métacaractère doit être placé soit en début de masque soit en début d’alternative pour qu’on puisse utiliser son sens spécial.
Le troisième masque nous permet cette fois-ci de chercher la présence d’une lettre majuscule de l’alphabet commun (lettre non accentuée et sans cédille) en début de chaine. Notez bien ici que j’utilise mon métacaractère ^ en dehors de ma classe de caractères.
Notre quatrième masque permet de chercher la présence d’un point d’interrogation en fin de chaine. Ici, il faut protéger le point d’interrogation pour le chercher comme caractère en tant que tel.
Notre cinquième et dernier masque est un peu plus complexe à comprendre. On utilise cette fois-ci à la fois le métacaractère ^ et le métacaractère $ ce qui va créer une vraie restriction sur ce qui va être recherché.
En effet, vous devez bien comprendre qu’ici on cherche une séquence de deux caractères avec le premier caractère qui doit être un « p » ou un « P » en début de chaine et le deuxième caractère qui doit être un « ? » et se situer en fin de chaine. On cherche donc exactement les chaines « p? » ou « P? ».
Nous allons voir ci-dessous comment spécifier qu’on cherche une chaine de taille quelconque qui commence par un certain caractère et se termine par un autre.
Les quantificateurs
Les quantificateurs sont des métacaractères qui vont nous permettre de rechercher une certaine quantité d’un caractère ou d’une séquence de caractères.
Les quantificateurs disponibles sont les suivants :
| Quantificateur | Description |
|---|---|
| a{X} | On veut une séquence de X « a » |
| a{X,Y} | On veut une séquence de X à Y fois « a » |
| a{X,} | On veut une séquence d’au moins X fois « a » sans limite supérieure |
| a? | On veut 0 ou 1 « a ». Équivalent à a{0,1} |
| a+ | On veut au moins un « a ». Équivalent à a{1,} |
| a* | On veut 0, 1 ou plusieurs « a ». Équivalent à a{0,} |
Bien évidemment, les lettres « a », « X » et « Y » ne sont données ici qu’à titre d’exemple et on les remplacera par des valeurs effectives en pratique.
<!DOCTYPE html>
<html>
<head>
<title>Cours PHP & MySQL</title>
<meta charset="utf-8">
<link rel="stylesheet" href="cours.css">
</head>
<body>
<h1>Titre principal</h1>
<?php
$masque1 = '/er?/';
$masque2 = '/er+/';
$masque3 = '/^[A-Z].{10,}\?$/';
$masque4 = '/^\d{10,10}$/';
$chaine = 'Pierre, 29 ans. Et vous ?';
$chaine2 = '0665656565';
preg_match_all($masque1, $chaine, $tb1);
preg_match_all($masque2, $chaine, $tb2);
preg_match_all($masque3, $chaine, $tb3);
preg_match_all($masque4, $chaine2, $tb4);
print_r($tb1);
echo '<br>';
print_r($tb2);
echo '<br>';
print_r($tb3);
echo '<br>';
print_r($tb4);
?>
<p>Un paragraphe</p>
</body>
</html>

Notre premier masque va ici nous permettre de chercher un « e » suivi de 0 ou 1 « r ». La chose à bien comprendre ici est que si notre chaine contient un « e » suivi de plus d’un « r » alors la séquence « er » sera bien trouvée puisqu’elle est bien présente dans la chaine. Le fait qu’il y ait d’autres « r » derrière n’influe pas sur le résultat.
Notez également que les quantificateurs sont dits « gourmands » par défaut : cela signifie qu’ils vont d’abord essayer de chercher le maximum de répétition autorisé. C’est la raison pour laquelle ici « er » est renvoyé la première fois (séquence présente dans « Pierre ») et non pas simplement « e ». Ensuite, ils vont chercher le nombre de répétitions inférieur et etc. (le deuxième « e » de « Pierre » est également trouvé.
Notre deuxième masque va chercher un « e » suivi d’au moins un « r ». On trouve cette séquence dans « Pierre ». Comme les quantificateurs sont gourmands, c’est la séquence la plus grande autorisée qui va être trouvée, à savoir « err ».
Notre troisième masque est plus complexe et également très intéressant. Il nous permet de chercher une chaine qui commence par une lettre de l’alphabet commun en majuscule suivie d’au moins 10 caractères qui peuvent être n’importe quel caractère à part un retour à la ligne (puisqu’on utilise ici le métacaractère point) et qui se termine avec un « ? ».
Finalement, notre quatrième masque va nous permettre de vérifier qu’une chaine contient exactement et uniquement 10 chiffres. Ce type de masque va être très intéressant pour vérifier qu’un utilisateur a inscrit son numéro de téléphone correctement lors de son inscription sur notre site par exemple.
Les sous masques
Les métacaractères ( et ) vont être utilisés pour délimiter des sous masques.
Un sous masque est une partie d’un masque délimités par un couple de parenthèses. Ces parenthèses vont nous permettre d’isoler des alternatives ou de définir sur quelle partie du masque un quantificateur doit s’appliquer.
De manière très schématique, et même si ce n’est pas strictement vrai, vous pouvez considérer qu’on va en faire le même usage que lors d’opérations mathématiques, c’est-à-dire qu’on va s’ne servir pour prioriser les calculs.
Par défaut, les sous masques vont être capturants. Cela signifie tout simplement que lorsqu’un sous masque est trouvé dans la chaine de caractères, la partie de cette chaine sera capturée.
<!DOCTYPE html>
<html>
<head>
<title>Cours PHP & MySQL</title>
<meta charset="utf-8">
<link rel="stylesheet" href="cours.css">
</head>
<body>
<h1>Titre principal</h1>
<?php
$masque1 = '/er|t/'; //Chercher "er" ou "t"
$masque2 = '/e(r|t)/'; //Cherche "er", "et", "r" et "t"
$masque3 = '/er{2}/'; //Cherche "e" suivi de "r" suivi de "r"
$masque4 = '/(er){2}/'; //Cherche "er" suivi de "er"
$chaine = 'Je suis Pierre et j\'ai 29 ans.';
preg_match_all($masque1, $chaine, $tb1);
preg_match_all($masque2, $chaine, $tb2);
preg_match_all($masque3, $chaine, $tb3);
preg_match_all($masque4, $chaine, $tb4);
echo '<pre>';
print_r($tb1);
print_r($tb2);
print_r($tb3);
print_r($tb4);
echo '</pre>';
?>
<p>Un paragraphe</p>
</body>
</html>

Notre premier masque n’utilise pas les métacaractères de sous masque ( ). Il nous permet de chercher « er » ou « t ».
Notre deuxième masque contient un sous masque. Ce masque va nous permettre de chercher « er », « et », « r » et « t » car je vous rappelle que les sous masques sont capturants : si un motif du sous masque correspond, la partie de la chaine de caractères dans laquelle on recherche sera capturée. Ici, notre sous masque chercher « r » ou « t ». Dès que ces caractères vont être trouvés dans la chaine, ils vont être capturés et renvoyés.
Notre troisième masque nous permet de chercher un « e » suivi du caractère « r » répété deux fois.
Notre quatrième masque, en revanche, va nous permettre de chercher la séquence « er » répétée deux fois.
Les assertions
On appelle « assertion » un test qui va se dérouler sur le ou les caractères suivants ou précédent celui qui est à l’étude actuellement. Par exemple, le métacaractère $ est une assertion puisque l’idée ici est de vérifier qu’il n’y a plus aucun caractère après le caractère ou la séquence écrite avant $.
Ce premier exemple correspond à une assertion dite simple. Il est également possible d’utiliser des assertions complexes qui vont prendre la forme de sous masques.
Il existe à nouveau deux grands types d’assertions complexes : celles qui vont porter sur les caractères suivants celui à l’étude qu’on appellera également « assertion avant » et celles qui vont porter sur les caractères précédents celui à l’étude qu’on appellera également « assertion arrière ».
Les assertions avant et arrière vont encore pouvoir être « positives » ou « négatives ». Une assertion « positive » est une assertion qui va chercher la présence d’un caractère après ou avant le caractère à l’étude tandis qu’une assertion « négative » va au contraire vérifier qu’un caractère n’est pas présent après ou avant le caractère à l’étude.
Notez que les assertions, à la différence des sous masques, ne sont pas capturantes par défaut et ne peuvent pas être répétées.
Voici les assertions complexes qu’on va pouvoir utiliser ainsi que leur description rapide :
| Assertion | Description |
|---|---|
| a(?=b) | Cherche « a » suivi de « b » (assertion avant positive) |
| a(?!b) | Cherche « a » non suivi de « b » (assertion avant négative) |
| (?<=b)a | Cherche « a » précédé par « b » (assertion arrière positive) |
| (?<!b)a | Cherche « a » non précédé par « b » (assertion arrière négative) |
<!DOCTYPE html>
<html>
<head>
<title>Cours PHP & MySQL</title>
<meta charset="utf-8">
<link rel="stylesheet" href="cours.css">
</head>
<body>
<h1>Titre principal</h1>
<?php
$masque1 = '/e(?=r)/'; //Chercher "e" suivi de "r"
$masque2 = '/e(?!r)/'; //Chercher "e" non suivi de "r"
$masque3 = '/(?<=i)s/'; //Cherche "s" précédé de "i"
$masque4 = '/(?<!i)s/'; //Cherche "s" non précédé de "i"
$chaine = 'Je suis Pierre et j\'ai 29 ans.';
$res1 = preg_match_all($masque1, $chaine);
$res2 = preg_match_all($masque2, $chaine);
$res3 = preg_match_all($masque3, $chaine);
$res4 = preg_match_all($masque4, $chaine);
echo 'La chaine complète est : "' .$chaine.'".<br>
Elle contient ' .$res1. ' "e" suivi d\'un "r". <br>
Elle contient ' .$res2. ' "e" non suivi d\'un "r". <br>
Elle contient ' .$res3. ' "s" précédé d\'un "i". <br>
Elle contient ' .$res4. ' "s" non précédé d\'un "i". <br>';
?>
<p>Un paragraphe</p>
</body>
</html>

Résumé : liste complète des métacaractères des expressions régulières
Voici la liste de tous les métacaractères qu’on va pouvoir utiliser en dehors des classes de caractères :
| Métacaractères | Description |
|---|---|
| \ | Caractère dit d’échappement ou de protection qui va servir notamment à neutraliser le sens d’un métacaractère ou à créer une classe abrégée |
| [ | Définit le début d’une classe de caractères |
| ] | Définit la fin d’une classe de caractères |
| . | Permet de chercher n’importe quel caractère à l’exception du caractère de nouvelle ligne |
| | | Caractère d’alternative qui permet de trouver un caractère ou un autre |
| ^ | Permet de chercher la présence d’un caractère en début de chaine |
| $ | Permet de chercher la présence d’un caractère en fin de chaine |
| ? | Quantificateur de 0 ou 1. Peut également être utilisé avec « ( » pour en modifier le sens |
| + | Quantificateur de 1 ou plus |
| * | Quantificateur de 0 ou plus |
| { | Définit le début d’un quantificateur |
| } | Définit la fin d’un quantificateur |
| ( | Début de sous masque ou d’assertion |
| ) | Fin de sous masque ou d’assertion |




